


|
Unicode Codec Tool
|
|
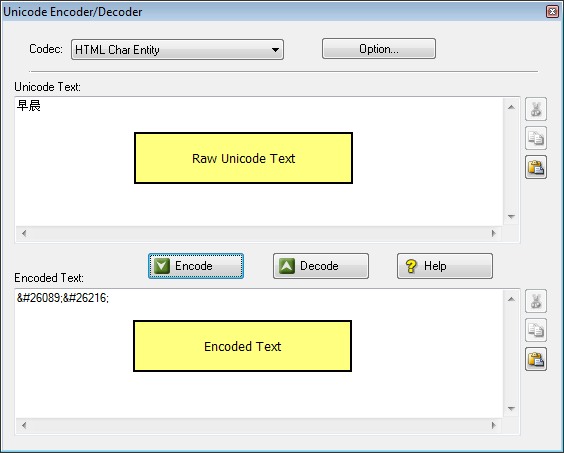
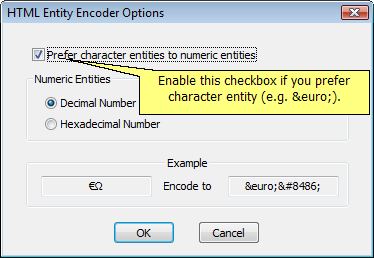
| · | You may drag-and-drop text file to text boxes. The program can detect the precense of Unicode BOM and read Unicode, Unicode Big Endian and UTF-8 text file. If no BOM is found, the program read the file using default system code page.
|